Language Modeling Based on Neural networks: An overview
Introduction
Language modeling tries to capture the notion that some text is more likely than others. It does so by estimating the probability of any text .
Formally, assume we have a corpus, which is a set of sentence. We define to be the set of all words in the language. In practice, is very large, but we assume it’s a finite set. A Sentence in the language is a sequence of words
where the integer is such that , we have for , and we assume that is a special symbol, STOP(we assume STOP is not a member of ). We will define to be the set of all sentences with the vocabulary , is a infinite set.
Definition: A language model consists of a finite set , and a function such that:
- For any ,
- In addition, , hence is a probability distribution over sentences in .
Methods
NGram Language Modeling
Here we will take a trigram language model as an example.
As in Markov models, we model each sentence as a sequence of n random variables, . The length n itself is a random variable. Under a second-order Markov model, the probability of any sentence is
where we assume . For any ,
is the parameter of the model. Note, the parameter size of a -gram language model grow exponentially as
Maximum-Likelihood Estimates
Define to be the number of times that the trigram is seen in the training corpus.
This estimate is very natural, but could run into a very serious issue. The number of parameters of our model is huge (e.g., with a vocabulary size of 10, 000, we have around parameters[I think there might be ]), many of our counts will be there, this lead to:
-
if the numerator is 0, . This will lead to many trigram probabilities being underestimated: it seems unreasonable to assign probability 0 to any trigram not seen in training data, given that the number of parameters of the model is typically very large in comparison to the number of words in the training corpus.
-
if the denominator is 0, the estimate is not well defined.
There are some smoothing methods to alleviate these issues, but we won’t go there here, you could find out more details in the references.
The performance of ngram language model improves with keeping around higher ngrams counts and doing smoothing and so-called backoff (e.g. if 4-gram not found, try 3-gram, etc).
Language Modeling based on Neural Networks
Languae model based on ngram seems promising. It’s intuitively simple and we could always make it more representative by increasing . However, the unique ngram counts go up exponentially as goes up, which means we need gigantic RAM to store those enormous amount of ngram counts. Neural network based methods have been exploited. The model size scales up with respect to vocabulary size(see section 2 of 10 for more details).
Feedforward Neural Network Language Modeling
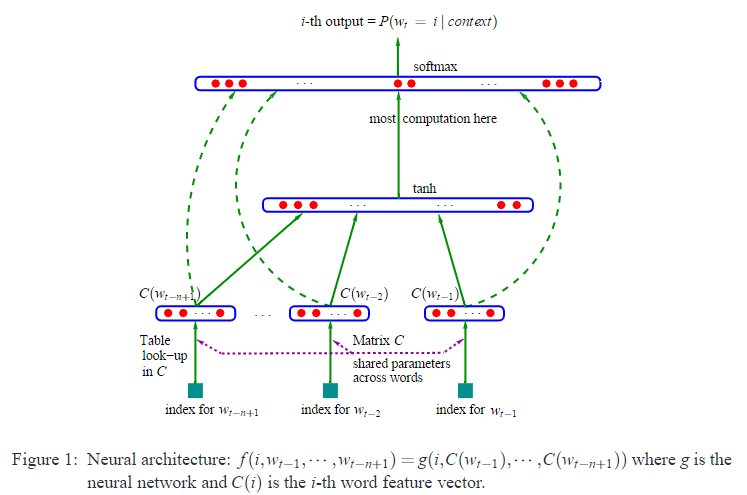
Architecture shown above models on the a slide window of the given sentence, which is . RAM requirement scales with number words and window size.
The Forward passing is described as follows:
Recurrent Neural Network Language Model
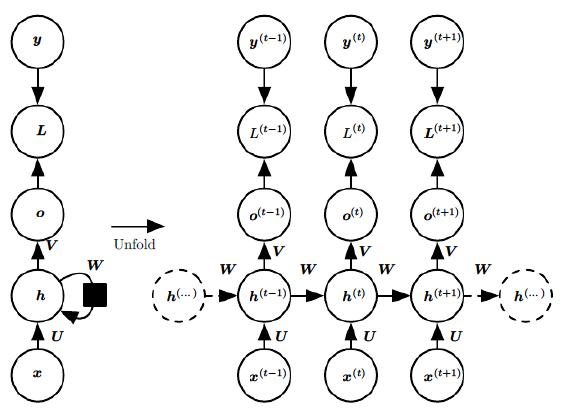
Forward Passing of rnn is described as follows:
A major deficiency of the feedforward approach is that a feedforward network has to use fixed length context that needs to be specified ad hoc before training, it models on . Usually this means that neural networks see only five to ten preceding words when predicting the next one. It is well known that humans can exploit longer context with great success. However, RNN encode the whole history into the state , this makes it models on .
Training Methods
Both feedforward neural network based language model and recurrent neural network based language model can be trained with back propagation with a cross entropy loss.
Evaluation Metrics
Perplexity
A common method to measure the quality of a language model is to evaluate the perplexity of the model on some held-out data.
Perplexity of a probability
The perplexity of a discrete probability distribution is defined as
where is the entropy of the distribution and x ranges over events.
Perplexity of a probability model
A model of an unknown probability distribution , may be proposed based on a training sample that was drawn from . Given a proposed probability model , one may evaluate by asking how well it predicts a separate test sample also drawn from . The perplexity of the model is defined as
where is commonly . Better models of the unknown distribution will tend to assign higher probabilities to the test events. Thus, they have lower perplexity: they are less surprised by the test sample.
The exponent above may be regarded as the average number of bits needed to represent a test event if one uses an optimal code based on . Low-perplexity models do a better job of compressing the test sample, requiring few bits per test element on average because tends to be high.
The exponent may also be regarded as a cross-entropy,
where denotes the empirical distribution of the test sample (i.e., if appeared times in the test sample of size ).
Perplexity of a language model
Using the definition of perplexity for a probability model, one might find, for example, that the average sentence in the test sample could be coded in bits (i.e., the test sentences had an average log-probability of ). This would give an enormous model perplexity of per sentence. However, it is more common to normalize for sentence length and consider only the number of bits per word. Thus, if the test sample’s sentences comprised a total of words, and could be coded using a total of (the wikipedia page says it’s , I think it should be ) bits per word, one could report a model perplexity of per word. In other words, the model is as confused on test data as if it had to choose uniformly and independently among possibilities for each word.
Sample Sentences from language model using temperature sampling
Temperature sampling works by increasing the probability of the most likely words before sampling. The output probability of each word is transformed by the freezing function to:
For , the probability transformed by freezing function is the same as the output of the softmax. For , the freezing function turns sampling into the argmax function, returning the most likely output word. For a low temperature , the transformed probability of the word with the highest softmax probability tends to 1. For , the freezing function is equivalent to squaring the probability of each output word, and then renormalizing the sum of probabilities to . The typical perspective I hear is that a temperature like is supposed to make the model more robust to errors while maintaining some diversity that you’d miss out on with a greedy argmax sampler. Maximum Likelihood Decoding with RNNs - the good, the bad, and the ugly digged more on the sampling process and he even proposes a generalized senmantic temperature sampling to solve semantic distortions introduced by classical temprature.
Reference
-
Bengio et al. Deep Learning, chapter 10 Sequence Modeling: Recurrent and Recursive Nets
-
Bengio et al. A Neural Probabilistic Language Model
-
Mikolov et al. Recurrent neural network based language model
-
Course notes for NLP by Michael Collins, Columbia University
-
Socher CS224d: Deep Learning for Natural Language Processing Lecture 8
-
Maximum Likelihood Decoding with RNNs - the good, the bad, and the ugly
-
Bengio, Morin. Hierarchical Probabilistic Neural Network Language Model