Neural Network tips and practices
This post aims at collecting reasons behind the common practices of training neural networks, as well as maintaining a list of reference on how to train them.
Notes of CS224d lecture[1]
BackPropagation
In backpropagation, we just want to comput the gradient of example-wise loss with respect to paramters. The main piece is to apply the derivative chain rule wisely. A common property in bp is if computing the loss(example, paramters) is computation, then so is computing the gradient.
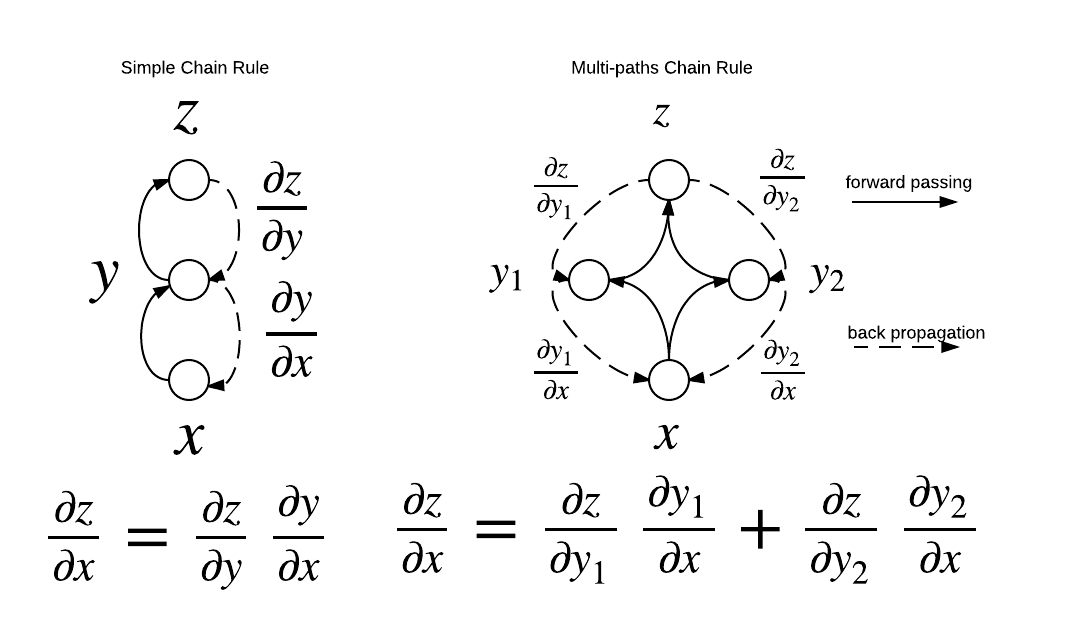
Figure 1. back propagation
- Forword Passing: visit nodes in topo-sort order, compute value of node given predecessors
- Back Propagation: visit nodes in reverse order, compute gradient with respect to node using gradient with respect to successor
Both operations are visualized in Figure 1.
Multi-task learing/weight sharing
We already knew that word vectors can be share cross tasks. The main idea of multi-task learning is instead of only word vectors, the hidden layer weights can be shared too. Only the final softmax weights are different. The cost function of multi-task learning is the sum of all the cross entropy errors.
General Strategy for Successful NNets
Select network structure appropriate for problem
Structure
- Model: bag of words, recursive vs. recurrent,CNN
- Model on: Single words, fixed windows, sentence based, or document level;
Nonlinearity
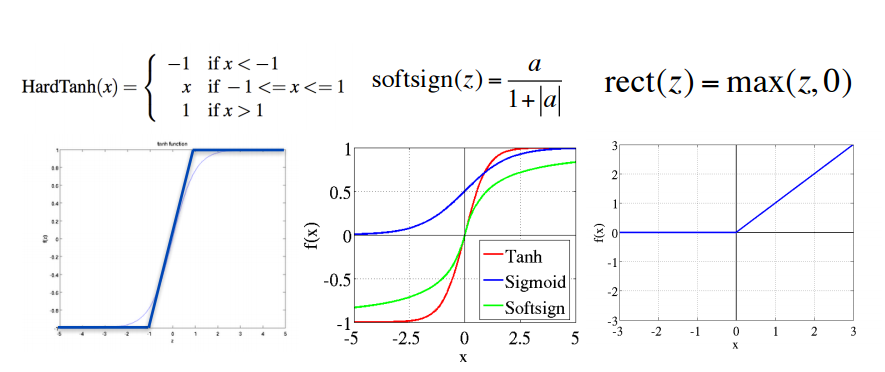
Figure 2. Different types of nolinearties.(Left): hard tanh; (center): soft sign, tanh and softmax; (right):relu
Check for implementation bugs with gradient checks
Gradient check allows you to know that whether there are bugs in your neural network implementation or not. just follow the steps bellow:
- implement your gradient
-
Implement a finite difference computation by looping through the parameters of your network, adding and subtracting a small epsilon() and estimate derivatives
- compare the two and make sure they are almost the same When work with tensorflow, this part could be skipped.
Parameter initialization
Before initialize paramter, make sure the input data are normalized to zero mean with small deviation. Some common practices on weight initializing:
- initialize hidden layer bias to 0
- initialize weights by sampling from , where inversely propotional to fan-in(previous layer size) and fan-out(next layer size). Normally, for sigmoid, for tanh.
Optimization tricks
Gradient descent uses total gradient over all examples per update, it is very slow and should never be used. Most commly used now is Mini-batch Stochastic Gradient Descent with a mini batch size between , the update rule is
where is the mini batch size.
Momentum
The idea of momentum is adding a fraction of previous update to current one.
where is initialized to .
When the gradient keeps pointing in the same direction, this will increase the size of the steps taken towards the minimum.
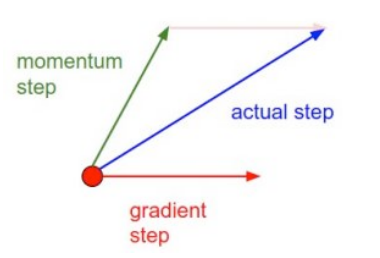
Figure 3. Single SGD update with Momentum
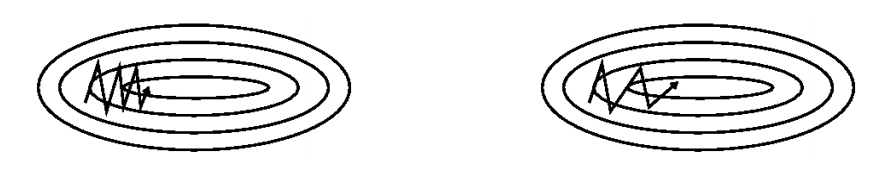
Figure 4. Simple convex function optimization dynamics: without momentum(left), with momentum(right)
However, when using a lot of momentum, the global learning rate should be reduced.
Learning Rates
The simpleest recipe is to keep it fixed and use the same for all parameters. Better results show by allowing learning rates to decrease Options:
- reduce by when validation error stops improving
- keep the learning rate constant for the first steps, and then reduce by
- better to handle learning rate via AdaGrad
AdaGrad
AdaGrad adapts differently for each parameter and rare parameters get larger uodates than frequently occuring parameters. Let
Check if the model is powerful enough to overfit
- If not, change model structure or make model “larger”
- If you can overfit: Regularize
Regularize
- Simple first step: reduce model size by lowering number of units and layers and other parameters
- Standard L1 or L2 regularization on weights
- Early stopping: Use parameters that gave best validation error
- Sparsity constrains on hidden activation, eg, add to cost
- dropout: randomly set of the inputs to each neuron to , and halve the model weights at test time. This prevent feature co-adaption, which means a feature can be useful even when other features do not present